| POINT | X | Y |
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 8 | 1 |
| 5 | 9 | 1 |
| 6 | 6 | 6 |
| 7 | 5 | 5 |
| 8 | 9 | 9 |
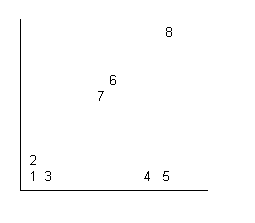
|
A Clustering Algorithm |
|
Clustering is the process by which discrete objects can be assigned to
groups which have similar characteristics. The objects might be animals of
different species and the purpose of the grouping might be to find those
species with the most similarities. The objects might be responses of individuals to a survey, and the
clusters might indicate the categories of response types. In the world of
satellite-collected image data, billions of pixel points could be grouped
into hundreds of clusters. This gross resolution of the data would allow a
person in the field to analyze the land-use data with a personal computer
rather than a supercomputer.
There are many algorithms used in clustering. The one presented here was described in the article "Finding Clusters: An Application of the Distance Concept" by Robert Clason in the April 1990 issue of The Mathematics Teacher. Each object is represented by an ordered n-tuple of its attributes. Objects with similar characteristics must have individual attributes which are close in value. Since distance is a measure of "closeness", it can be used in clustering. For each cluster, there will be a single point which is designated as a hub. The placement of the hub within the cluster is determined by the algorithm. We will start with two-dimensional objects since they are the easiest to visualize. Suppose we have 8 points in the configuration below. Draw circles around the clusters that you see visually. |
|
|
|
Let's see what a computer model of clustering would give us.
This algorithm assumes a minimum of 2 clusters and a maximum of p clusters where p is the number of objects. The algorithm is as follows:
Student Exercises
Exercise NotesExercise 3:The data might represent the unemployment rate and average housing costs in major U.S. cities. Since the differences in housing costs will be numbers in the 10000's and differences in the unemployment rates will be less than 10, the distance between points will be primarily determined by the housing costs. If unemployment is just as important as housing to the researcher, a method must be used to re-scale the data so that relative, rather than absolute, differences are used.
Exercise 4:
On to the Matlab Clustering Program. |
|
|